Introducción
Hace unos días estaba haciendo scraping con powershell y necesitaba descargar archivos (concretamente imágenes) de un sitio web, pero me encontré con el problema que esta página, One.com de ahora en adelante, carga las imágenes desde un sitio externo Piece.com de ahora en adelante ;)
Además, cuando accedí a las imagenes directamente en Piece.com el servidor Nginx me responde con un código 403 Forbidden es por eso que en este post les enseñaré el procedimiento para obtener las URL’s y automatizar la descarga de las imágenes además de hacer un bypass con una cabecera muy sencilla.
Analisis
La url inicial tiene la siguiente estructura: One.com/viewer/1000 y cuando ingresamos con un navegador luce más o menos así:
Además arriba y abajo de la imagen podemos ver un selector con el numero 1 al 22 y cada vez que cambiamos de selector por ejemplo 10, este numero se pone al final de nuestra url.
La imagen a descargar es lo primero que se ve, y al abrir el inspector de elementos (Ctrl+C) y seleccionar la imágen me di cuenta que One.com carga el recurso desde una estructura img1.Piece.com/uploads/AAAAMMDD/abc123/xyz.jpg. i 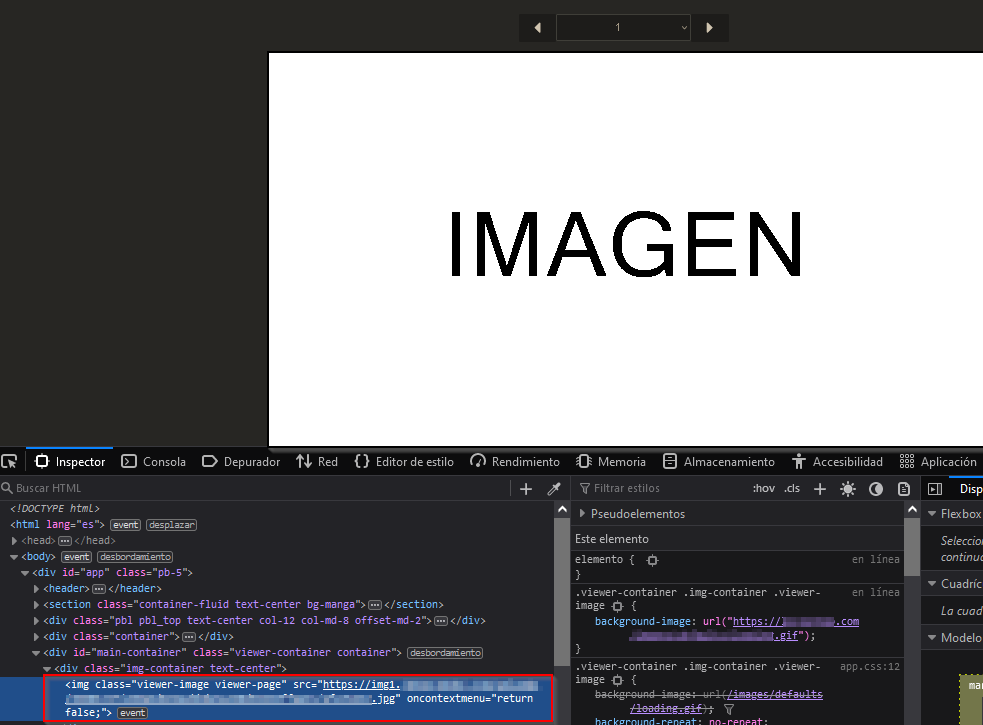
La imágen no tiene un nombre seriado, por ejemplo, 0001_org.jpg esto evita el problema con IDOR’s pero complicó el trabajo de scraping ya que la imágen tiene un nombre aleatorio para el selector 2, 3 ,4 , etc. Además, cuando quería abrir la imágen directamente con la url encontrada, el servidor responde con un 403 Forbidden.
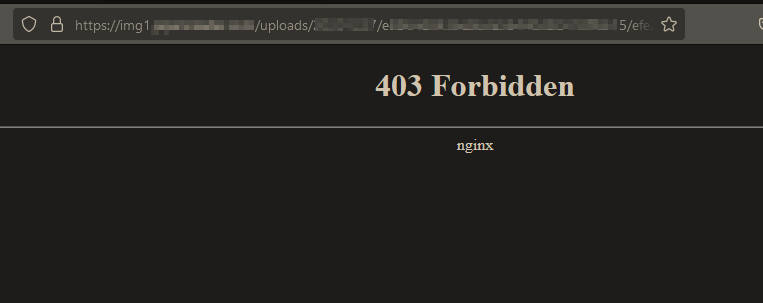
Aquí abrí el inspector del navegador y me dí cuenta que en el apartado de red cada que recargaba la página el server arrojaba el mismo código de estado.
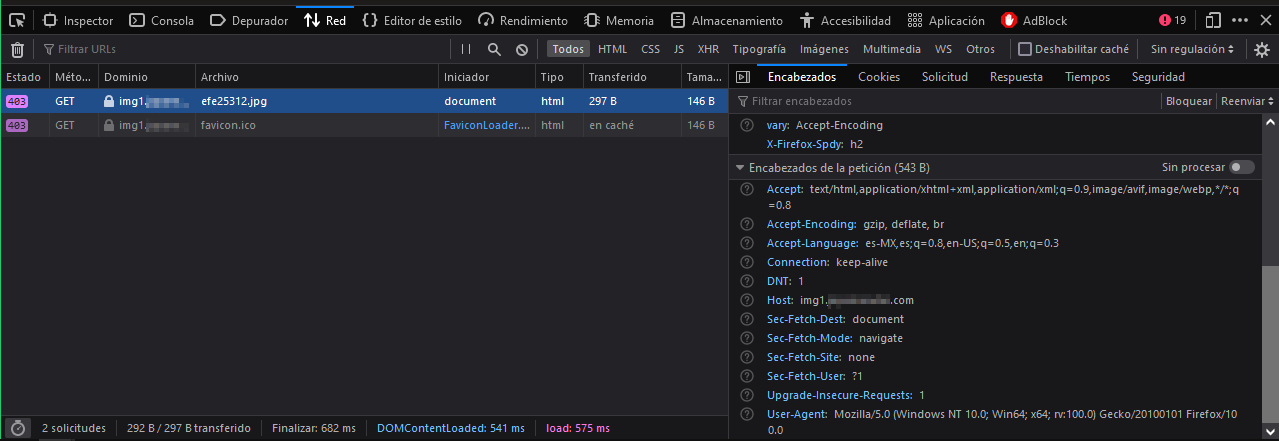
Después de pasar un rato comparando las peticiones, recursos cargados y finalmente las cabeceras de la petición, me dí cuenta que cuando One.com carga la imagen desde Piece.com envía la cabecera Refer: https://One.com
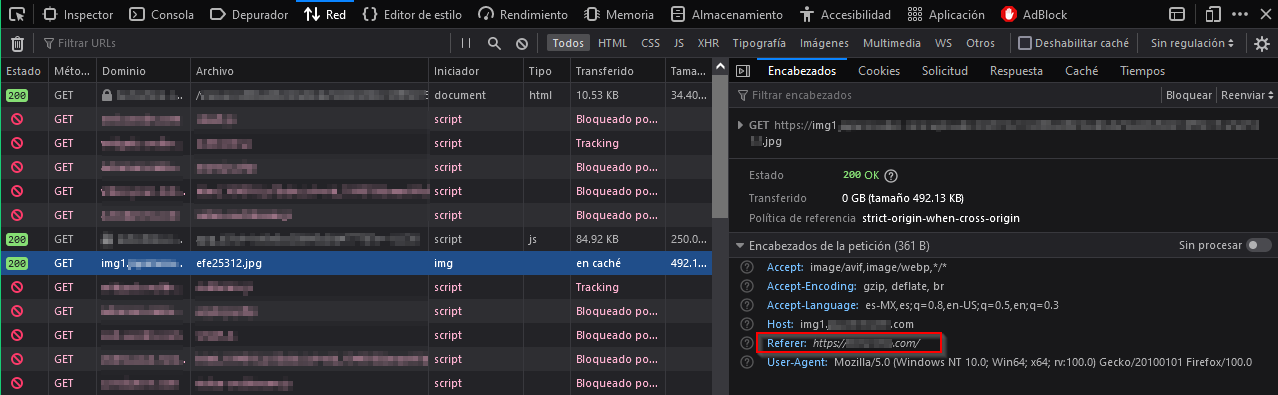
Esta cabecera sirve para indicarle al servidor Piece.com que el recurso se está solicitando o se está visitando desde One.com. Esta información puede ser usada para analytics, loggeo, cacheo y otras funciones, para saber más pueden visitar el siguiente enlace: https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Referer
Como prueba edité y reenvié la petición con el navegador agregandole la cabecera Refer: One.com la final
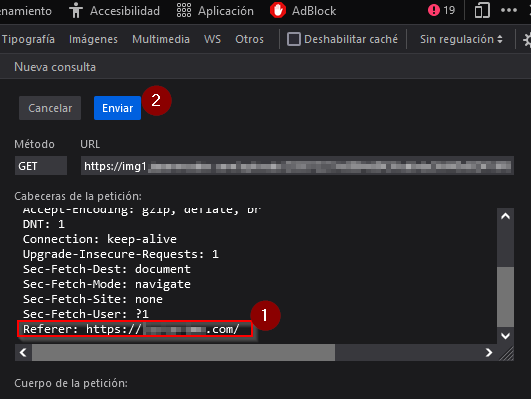
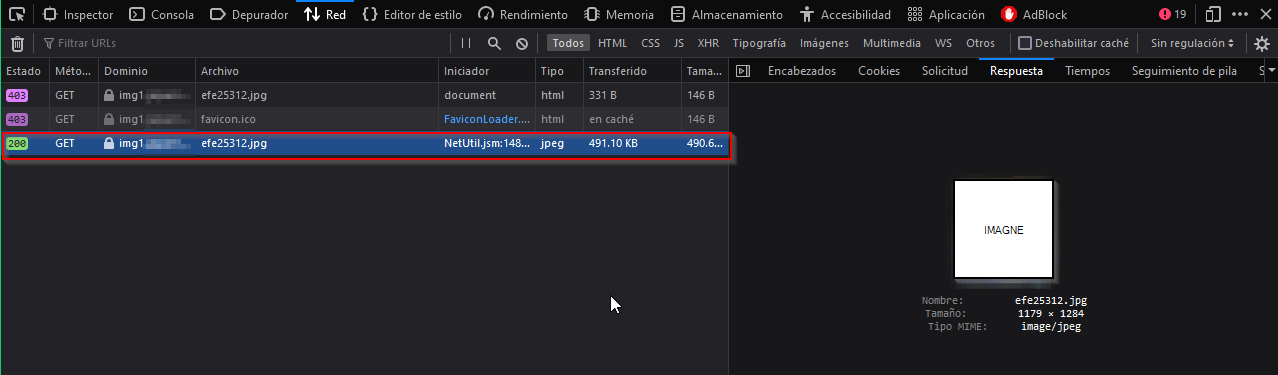
Como resultado el server me regresó la imagen sin restricciones y haciendo más pruebas encontré que no hace falta agregar más cabeceras
Código
Después de ver el comportamiento del server empecé a hacer el script que me permitiera automatizar la descarga de las imágenes en cada selector. Aquí el script final:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
$url = "https://One.com/viewer/1000"
$cabeceras=@{'Referer' = 'https://One.com/'}
$carpeta = "Descarga\\1000"
if(!(Test-Path -Path $carpeta))
{
New-Item -ItemType Directory -Path $carpeta
Write-Host "Ya existe el directorio" $carpeta
}
for($i=1;$i -le 22; $i++)
{
$datos = Invoke-WebRequest -Uri "$($url)/$($i)" -UseBasicParsing
$datos.Content -match '<img src="(?<IMAGEN>.*.jpg)"'
$salida="$($carpeta)\\$($i).jpg"
if($i -le 9)
{
$salida="$($carpeta)\\0$($i).jpg"
}
Invoke-WebRequest -Headers $cabeceras -Uri $Matches.IMAGEN -OutFile $salida -UseBasicParsing
Start-Sleep -Milliseconds 2000
}
Explicación del código
En la primera línea declaramos la variable $url que apunta a la dirección del grupo de imagenes que vamos a descargar, asignamos la cabecera refer a la variable $cabecera para descargar la imagen sin error y declaramos el nombre de la carpeta donde se guardarán las imagenes.
1
2
3
4
5
$url = "https://One.com/viewer/1000"
$cabeceras=@{'Referer' = 'https://One.com/'}
$carpeta = "Descarga\\1000"
Este bloque if crea la carpeta de descarga si no existe.
1
2
3
4
if(!(Test-Path -Path $carpeta))
{
New-Item -ItemType Directory -Path $carpeta
}
Inicio de ciclo for de 1 a 22 que corresponde a cada selector.
1
for($i=1;$i -le 22; $i++)
Se concatena $url y $i y quedaría https://One.com/viewer/1000/1, se hace una petición y la respuesta se almacena en $datos.
1
$datos = Invoke-WebRequest -Uri "$($url)/$($i)" -UseBasicParsing
Aquí utilicé -match para que busque en la respuesta ($datos.Content) la etiqueta HTML img src= y que concretamente guarde el valor de src, es decir, la url de la imágen en un campo que se llamará IMAGEN, con los parentesis estamos indicando el patrón a buscar y la expresion regular sería algo como esto: \".*\.jpg\"
1
$datos.Content -match '<img src="(?<IMAGEN>.*.jpg)"'
$salida indica la estructura del nombre de la imagen y junto con el bloque if le dan orden a las imagenes, cuando $i vale menos que 9 se le agregará un 0 al nombre del archivo, así quedaría 01.jpg 02.jpg 03jpg, etc.
1
2
3
4
5
6
$salida="$($carpeta)\\$($i).jpg"
if($i -le 9)
{
$salida="$($carpeta)\\0$($i).jpg"
}
Finalmente, se hace una petición enviando la cabecera Refer, usamos el campo IMAGEN del objeto Matches como url, le indicamos que guarde la respuesta como un archivo con el nombre de la variable $salida y después esperará 2 segundos por que de lo contrario el sitio nos banea por demasiadas peticiones en un lapso de tiempo muy corto.
1
2
Invoke-WebRequest -Headers $cabeceras -Uri $Matches.IMAGEN -OutFile $salida -UseBasicParsing
Start-Sleep -Milliseconds 2000
Conclusiones
El scraping nos permite automatizar muchas tareas cuando estamos en busca de archivos, sin embargo, muchos servidores limitan el acceso a los recursos con este tipo de restricciones por lo cual es importante conocer estas técnicas simples pero eficaces ;).